From TDD to Lightweight FM: Verifying Vibes with Specification-First Coding
Test-Driven Development
Test-driven development (TDD) is typically taught as a software engineering best practice, but frankly, writing tests first – before implementing the code under test – is too cumbersome for most startups and teams under pressure to ship fast.
The real value of TDD isn't just in testing code; it's in the tests' role as a specification for what the code is meant to do. This specification provides a clear source of truth outlining expected behaviors, edge cases, and interfaces, clarifying what it would actually mean for the code to be "correct" and ready to be merged into prod.
Unfortunately, unit tests make mediocre specs. Typically, the number of possible inputs to the code under test is infinite, so no set of unit tests can be truly comprehensive. Moreover, the same engineer who writes the unit tests typically writes the code under test, meaning they invariably bake the same implicit assumptions into both – leading to missed bugs (and an unreasonable sense of certainty that the code is right). Consequently, developers frequently abandon strict TDD in favor of light interactive testing (for example in a REPL or browser) or testing on customers.
Vibe Coding
Today, the popularity of "vibe-coding" – rapid, intuition-driven development, accelerated by AI copilots like Windsurf, Claude Code, and Cursor – further diminishes structured upfront planning. Vibe-coders rarely write test suites ahead of time, rather, they chat with an AI and interact directly with the code being generated until it both successfully compiles and superficially works as expected. Vibe-coding sacrifices rigid correctness and knowledge of committed code at the altar of speed. The result is often a form of elusive correctness, where the code appears to work on the two or three examples the developer tells the agent to work off of, but concretely relies on hard-coded values and janky helper functions that don't generalize to production-scale inputs.
Can we Vibe Tests?
Even the latest frontier models, such as o1, struggle significantly with generating valid unit tests. This is because LLMs are essentially sophisticated pattern recognition machines. They skim codebases and make predictions based on statistical weighting rather than actual code execution. In order to generate a correct unit test, the LLM would need to know what the expected output of the code under test is; but if it knew this, we could just ask the LLM rather than running the code in the first place. We can't, because the LLMs hallucinate.
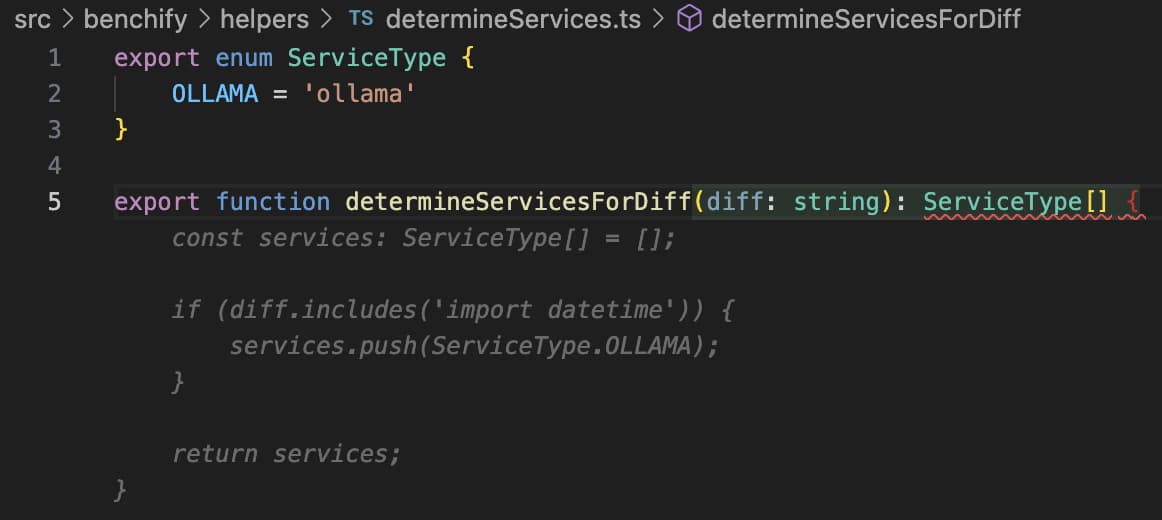
Hallucination is not a simple engineering problem solvable given sufficient research. It is a fundamental, invariable aspect of large language models. LLMs predict in-distribution; they make mistakes out-of-distribution. Those mistakes are called hallucinations. We can minimize hallucinations by creating better and better models and training on more and more data, but we can never eliminate them.
As a concrete example, suppose you're programming a Strava competitor and need to implement the Haversine distance in order to compute route lengths. To generate a unit test for your implementation, an LLM would need to choose two latitude/longitude pairs, and determine the correct Haversine approximation of the distance between them. But the LLM has no way of performing this calculation; it can only guess each digit based on the statistical distribution of its training data. So it'll write an incorrect test every single time. For example, here's a unit test written by Cursor. It's wrong; the correct distance is 877.5.
import unittest
class TestHaversineDistance(unittest.TestCase):
def test_distance_between_two_points(self):
# Berlin coordinates
lat1, lon1 = 52.5200, 13.4050
# Paris coordinates
lat2, lon2 = 48.8566, 2.3522
# Approximate distance in kilometers
expected_distance = 878.84
distance = haversine_distance(lat1, lon1, lat2, lon2)
self.assertAlmostEqual(
distance,
expected_distance,
delta=1,
msg=f"Expected {expected_distance}, but got {distance}"
)
Safer Vibing
Ironically, as vibe coding becomes more popular, the need for a clear, single source of truth only grows. LLM-generated code can be ambiguous, inconsistent, and nondeterministic. Without clear specifications, developers risk creating unreliable or unpredictable products.
An area of mathematical computer science known as formal methods offers a theoretically robust alternative. The idea is to write a mathematically rigorous specification precisely stating what your code is meant to do, covering all the possible edge-cases, and then compare your code to this spec. Concretely, the spec is a list of logical properties describing how the code should function for all possible inputs. Unfortunately, formal methods are generally impractical for production software teams, typically requiring teams of PhDs (such as Max) to write detailed models and theorems in order to produce useful results. Thus, formal methods are typically only used in high-stakes industries like aerospace or cybersecurity, leaving them inaccessible to most developers.
What's needed is a practical middle ground: a kind of TDD that begins with a specification (what is the code meant to do?) and results in a holistic test suite. It's not about strictly writing tests first; it's about consistently capturing intent and behavior through checkable specs, so we can ensure the vibed code actually accomplishes the viber's goals. This middle ground can be found in lightweight formal methods.
Lightweight formal methods are techniques that can automatically compare code to a logical spec, i.e., a list of properties saying how the code should behave relative to all inputs. For example, whereas a unit test might assert that the distance from Berlin to Paris is 877.5 km, a property for the Haversine distance could state that for all locations A and B, the distance from A to B is the same as the distance from B to A; or that the distance from A to A should always be zero.
def prop_haversine_symm_id(A: Tuple[float, float], B: Tuple[float, float]):
# Test symmetry: distance A→B equals distance B→A
AtoB = haversine_distance(A[0], A[1], B[0], B[1])
BtoA = haversine_distance(B[0], B[1], A[0], A[1])
assert AtoB == BtoA, "The Haversine distance is not symmetric"
# Test identity: distance from point to itself is zero
AtoA = haversine_distance(A[0], A[1], A[0], A[1])
assert AtoA == 0, "The Haversine distance from a point to itself is non-zero"
Lightweight formal methods are formal enough to vastly outperform traditional unit tests, but straightforward enough to be usable without PhD-level manual analysis and interpretation. Moreover, they elide the problem of hallucinated values in LLM-generated unit tests, because they reason about the code at a higher level of abstraction, without relying on specific predetermined input/output values (like the latitude/longitude of Berlin or the distance from Berlin to Paris).
Our Mission
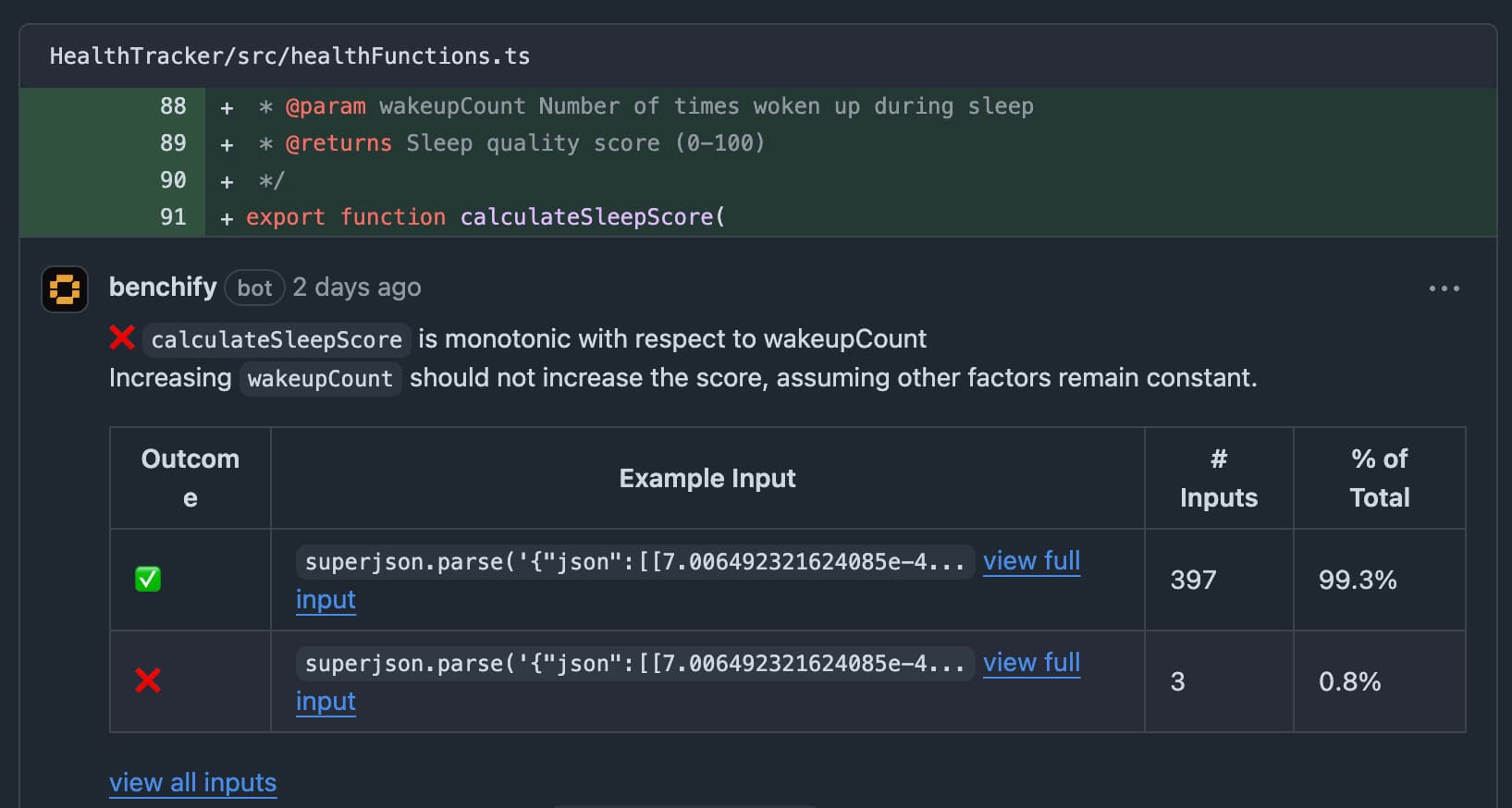
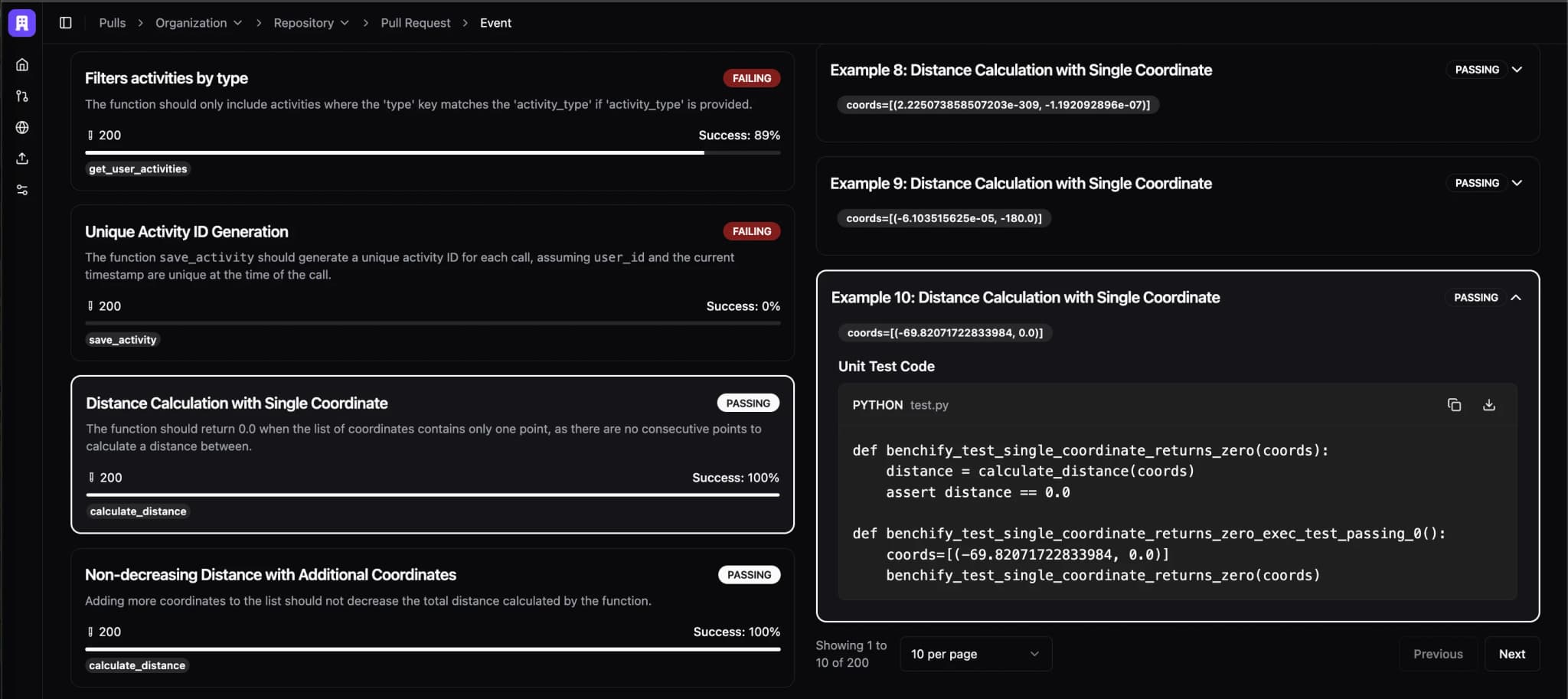
At Benchify, we're pioneering an advanced code review platform that automatically writes properties describing how your code should function, and then analyzes your code relative to that spec using lightweight formal methods. Our solution combines the rigor and power of FM with the ergonomic simplicity and user-friendliness that developers expect from LLM-based tools. Benchify runs sophisticated test harnesses designed to identify nuanced failure cases, proactively surfacing these findings in an intuitive, actionable manner.
In addition, we're building simple interfaces for developers to write, view, edit, and generate properties for their code, and then launch powerful fuzz campaigns against those joint specifications. In other words: we're building specification-first coding.
We're making rigorous testing and clear specifications accessible to every developer. If you want to vibe, sign up for Benchify and try it for free! And if you're interested in helping us make the world's best testing platform, send your resume to founders@benchify.com.